Real time OS basics
Contents
| Definitions | Some basic definitions regarding real time concepts and operating systems |
| Kernel | Simple schedulers, non-preemptive and preemptive kernals |
| Synchronization and communication primitives | The need for mutual exclusion and synchronization, semaphores, signals, message queues |
Definitions
This chapter defines and explains some words used in the real time pages. Some words are used in slightly different ways by different persons, and discussions on these words can often be found in discussion groups on the internet.
| Thread | A thread is the primitive that can execute code. It contains an instruction pointer (= program counter) and sometimes has its own stack. |
| Process | An environment in which one or several threads run. Examples of
the context is the global memory address, which is common for threads
within a process. Note that a process in itself does not execute code,
but one or more threads within the process can.
In some systems that does not have memory protection threads are sometimes called processes. This should be avoided since it will only lead to confusion. |
| Task | In this text, a task is something that needs to be done. It is often implemented in a separate thread, but does not have to be. |
| Kernel | The kernel of an RTOS is the part that schedules which thread gets to execute at a given point in time. |
| Preemption | When a thread is interrupted, and the execution is handed over to another thread using a context switch. |
| Context switch | The execution is changed from one context (thread) to another. |
One shot threads vs conventional threads
There are two types of threads which can distinctively be distinguished. These are single shot threads and conventional threads.
Single shot threads
A single shot thread can have three different states - ready, running and terminated. When it becomes ready to run, it enters the ready state. Once it get the CPU time, it enters the running state. If it is preempted by a higher priority thread, it can go back to ready state, but when it is finished, it enters terminated state.
What should be noticed here is that a single shot thread has no waiting state. The task can not yield the processor and wait for something (like a time or an event) and then continue where it was. The closest thing it can do is, before it terminates, it makes sure that it is restarted when a time or an event occurs.
Single shot threads are well suited for time driven systems where one wants to create a schedule offline. Single shot threads can be implemented using only very little RAM memory, and are therefore often used in small systems.
To summarize, a single shot thread behaves much like an interrupt service
routine - something starts it, it is preempted by higher priority interrupts
and when it is finished it terminates.
Conventional threads
In comparison with single shot threads, conventional threads have an extra state, the waiting state. This means that a conventional thread can yield the processor and wait for a time or an event to occur.
In systems using conventional threads, threads are often implemented
using while loops:
void blocking_task(void)
{
while (1)
{
/* task code */
delay(500);
/* do stuff */
...
}
}
Unlike single shot threads, many conventional threads will never enter the terminated state. It is not necessary since lower priority threads can run while the thread is in its waiting state.
Conventional threads give the programmer a higher degree of freedom compared to single shot threads, but as always that comes at a price. Usually the price is RAM and ROM memory, and sometimes also more CPU overhead.
Priorities
In operating systems that support preemption, threads normally have priorities. A thread that becomes ready to run can preempt an executing lower priority thread. Threads which perform critical tasks or have short deadlines often have higher priority.
A thread may have two different priorities - the base priority and the current priority.
- The base priority is the priority given to the thread by the programmer.
- The current priority is the one that is compared between threads and decides if a thread is allowed to run or not..
Normally the current priority is the same as the base priority, but in some cases it can be raised to a higher level. That will be described later in the chapter on Synchronization and communication primitives.
Note that in most RTOSes a higher priority means a lower priority number.
The kernel
Introduction
The kernel is the part of the operation system which controls which thread is run at each point in time. It is the kernel on which the rest of the OS is built.
Scheduler
In small systems, often using 8 or 16 bit micro controllers, the RAM memory and CPU time are limited resources. In such systems, a true RTOS may use too much of these resources. A simple schedules is often used to control how different tasks shall be run.
When a simple scheduler of this kind is used, threads are one shot and preemption is not used.
Simple scheduler
The simplest of schedulers, where each tread is run once every tick, can be implemented as in the example below:
void Scheduler(void)
{
int stop=0;
int newtick=0;
while(!stop)
{
while(!newtick); // Wait for timer tick
newtick = 0;
thread1();
thread2();
...
threadn();
if(newtick) // overrun
OverrunHandler(); //Could make reset depending on application
}
}
The scheduler is in a while loop, waiting for the newtick variable to be
increased by a timer interrupt. Once it has been received, the threads are
run and last the scheduler checks if there has been an overrun - if the
threads took too much time so that the next timer tick has already started.
An error handling routine is then called.
Extensions to the simple scheduler
The simple scheduler above could only run threads having a common cycle time. The extension below is a little bit more useful, and is used with some variation in many micro controllers.
void Scheduler(void)
{
int stop=0;
int newtick=0,oldtick=0;
while(!stop)
{
while(newtick==oldtick); // Wait for timer tick
oldtick = newtick;//threads running with minimum cycle time
thread1();
thread2();
switch(newtick % MAX_CYCLE_TIME)
{
case 0:
thread3();
thread4();
...
break;
case 1:
...
case MAX_CYCLE_TIME-1:
...
break;}
//more threads with min cycle time
...
threadn();
if(newtick!=oldtick) // overrun
OverrunHandler(); //Could make reset depending on application
}
}
Inside the switch statement threads with longer cycle times are placed. One can vary the times by running the same thread in more than one case statement.
Non-preemptive kernels
A simple scheduler as described above does really bot qualify as a real time kernel. Kernels are usually divided into two groups - preemptive or non-preemptive kernels.
In non-preemptive systems, a thread which has started to execute is always allowed to execute until one of two things happen:
- The executing thread is terminated.
- The executing thread inters its waiting state, for example by calling a 'wait' or 'delay' function, or by waiting for event other than a certain time.
When one of the things above has happend, the kernel performs a context switch.A context switch means that the kernel hands over the execution from one thread to another. The thread which is ready to run and has the highest priority gets to run.
What can be noticed here is that once a thread has started to execute, it is always allowed to continue to run until it itself chooses to yield the execution to some other thread. That also means that if a low priority thread has started to execute, a high priority thread which gets ready to run may have to wait for a considerable amount of time before it gets to execute.
Preemptive kernels
In preemptive systems, the kernel schedules is called with a defined period, each tick. Each time it is called it checks if there is a ready-to-run thread which has a higher priority than the executing thread. If that is the case, the scheduler performs a context switch. This means that a thread can be preempted - forced to go from executing to ready state - at any point in the code, something that puts special demands on communication between threads and handling common resources.
Using a preemptive kernel solves the problem where a high priority thread has to wait for a lower priority thread to yield the processor. Instead, when the high priority thread becomes ready to run, the lower priority thread will become preempted, and the high priority thread can start to execute.
Most commercial RTOSes support preemption.
Scheduling Policies
It is essential to understand the scheduling policy of the kernel that is used, since different policies allows for different programming styles and have different requirements. An identical program can behave quite differently when different scheduling policies are used!
The most common fixed-priority scheduling policies are:
- FIFO - a thread executes until it is finished, or a higher priority thread wants to run, but is never preempted by a thread with the same priority.
- Round robin - as above, a thread is preempted if a higher priority thread wants to run. If there are several threads of the same priority, each gets to run a predefined amount of time and is then put last in the queue in order to allow the next thread to execute.
A number of policies exist where the priority of a thread is changed depending on how much execution time it has used lately. Most Unix systems use such policies. They are however uncommon in real time systems, since it is difficult to create predictable systems using such policies.
Synchronization and communication primitives
In a complete system, threads almost always have to cooperate in order to make the system work. Two kinds of cooperation can be identified:
- Synchronization - Since time is important in real time systems, it can be important to synchronize threads in order to make them execute in a predefined order.
- Communication - Often threads need to exchange information in order for a task to be completed. An example is a system where one thread reads input from a user, another thread uses this input in its calculations, and a third thread shows the output of those calculations to the user. It may be a contol system, where the user sets the setpoint and reads the actual value of the property under control.
The need for synchronisation and communication between threads are the same in a non-realtime OS like Windows or UNIX as in a realtime OS and the synchronisation and communication primitives are often the same even if the interfaces may look different in different systems. You can read more about these things as well as many other things about operating systems in the book "Modern operating systems" by Andrew S Tanenbaum.
Here a number if solutions for systems using convensional threads will be described.
The need for protection
Resources that are common to several threads are called common resources. Common resources can include shared memory (like shared variables) and I/O units like a keybord, an UART or a CAN controller.
Problems can occur if more than one thread tries to access a common resource at the same time.
An example:
Thread A: N=N+1
Thread B: N=N-1
Assume that N has the initial value of 5.
If thread A is run first, and then thread B, the result will be 5. The same
is true if thread B runs first and then thread A. However, it is also
possible that the result will be 4 or 6!
Consider the following case:
| Thread A: LOAD R1, N ADD R1,1 STORE R1, N |
Thread B: LOAD R2, N SUB R2, 1 STORE R2, N |
- Thread A runs and loads the value of N (5) into register R1. It is then preempted by thread B which loads N /5) into register R2, subtracts it an stores the result (4) back into N. Now thread A gets to continue. Since it already loaded the value 5, it increments by one and stores the value 6 into N.
- By exchanging when the threads A and B run, the result will instead be 4.
Where the results depend of the exact timing of the threads like in the example one refers to it as a race condition. It is clear that something needs to be done to make sure that the same variable (and other resources) are not manipulated by more than one thread at a time. That is called mutual exclusion. There are several primitives to do that, and some of them are listed below with a short explanation.
The need for synchronization
Nothing here yet
Disabling interrupts
The simplest and easiest way to make sure that a thread is not preempted by another thread while accessing a shared resource is in many systems to disable the interrupts while the common resource is used. Since the scheduling is controlled by interrupts, no context switch can be made while interrupts are turned off.
This is a very crude and not a recommended way to achieve mutual exclusion. It is especially bad if the time needed for accessing the shared resource is long. First, there are often other things like hardware drivers that are controlled by interrupts. Turning off interrupts can cause problems for these or cause them to fail completely when interrupts are delayed or lost. The scheduler itself will be affected, since the random delays caused by turning off interrupts will cause jitter. Since this page is about real time systems, let's agree that turning off interrupts in order to achieve mutual exclusion is generally not a good idea!
Semaphores/Mutexes
Semaphores and mutexes are the classic ways of protecting shared resources, such as variables stored in shared memory. A semaphore is nothing more than a variable that can be increased, decreased and tested without being interrupted by another thread. Functions to manipulate a semaphore are supplied by the RTOS. The functions in principle look llike the examples below, although these examples don't have code in place to make the relevant parts of them atomic.
WaitSemaphore(Semaphore s) // Acquire Resource
{
wait until s > 0, then s := s-1; /* must be atomic once s > 0
is detected */
}
SignalSemaphore(Semaphore s) // Release Resource
{
s := s+1; /* must be atomic */
}
InitSemaphore(Semaphore s, Integer v)
{
s := v;
}
One semaphore is used for each resource that should be protected. The resource should be a variable, a set of variables, a piece of hardware etc. A thread that wants to use the shared resource first has to accuire the semaphore. If the semaphore was free - its counter was non-zero - the thread is allowed to continue. When it is done using the shared resource, it calls the function to release the semaphore. That increases the semaphore counter.
If the semaphore counter is already zero when a thread tries to accuire it, the thread must wait until the semaphore is released by another process. In order to avoid busy waiting (waiting in a loop, thus using lots of unnessecery CPU time) the thread is moved to a specific queue and put in waiting state. When a thread releases the semaphore, a thread waiting in the queue is be removed from the queue and put into the ready state. Which thread is chosen depends on the implementation - it could be the first one in the queue (FIFO) or it could be the one with the highest priority.
In order to protect shared memory, the semaphore counter should be initialised to one since only one thread at a time should be able to access the shared memory. Such a binary semaphore is called a mutex.
The use of semaphores in our little example from above would be:
| Thread A: WaitSemaphore(SemaphoreName); N = N+1 SignalSemaphore(SemaphoreName); |
Thread B: WaitSemaphore(SemaphoreName); N = N-1 SignalSemaphore(SemaphoreName); |
So if a mutex is enough to protect a shared resource, what is the use of other semaphores? Well, semaphores can be used for other things as well. Think of a server that handles requests from clients and spawns a new thread for each new request. A semaphore could there be used to limit the number of spawned threads running at the same time. If instead the server as one thread for recieving new requests and only one worker thread to execute them, the recieving thread can "release" the semaphore once of each request and the worker thread can accuire it for every request that is done. When the worker thread is done with all of the requests, it will be put into the semaphore queue and will be waiting until a new request is recieved. In this latter example the recieving and working threads will probably have to exchange more information than "one more request" which means that a further resource and protection for that is needed.
Semaphores is a basic way of protecting resources but is still used today.
Read more about semaphores at wikipedia.
Problem 1: Deadlock
There are two basic and common problems that occur with multithreaded systems. There are called deadlock and priority inversion.
A deadlock is a situation where two or more threads wait for eachother to relase common resources and no thread can continue to run. Consider the following example, where semaphore 1 protects N and semaphore 2 protects M:
| Thread A: WaitSemaphore(Semaphore1); WaitSemaphore(Semaphore2); N = N+M SignalSemaphore(Semaphore2); SignalSemaphore(Semaphore1); |
Thread B: WaitSemaphore(Semaphore2); WaitSemaphore(Semaphore1); N = N-M SignalSemaphore(Semaphore1); SignalSemaphore(Semaphore2); |
If thread A grabs semahore 1 and is then preempted by thread N, thread B will grab semaphore 2 and then wait for thread A to release semaphore 1. But when thread A gets to continue processing, it will immediatly start waiting for thread B to release semaphore 2. They will wait for eachother an neither thread will be able to continue. A deadlock has occured.
In this example the reason for the deadlock can be quite easily found and a solution can be quickly implemented - make sure that both threads grab the semaphores in the same order. In a more complex system however the reason for a deadlock can be much harder to find. It is made harder by the fact that the deadlocks may occor intermittently - they may occur only if the context switch happens at a specific place in a thread.
Problem 2: Priority inversion
We use priorities in order to make sure that threads with higher timing requirements can run first and meet their important deadlines. There are however cases when a high priority thread have to wait for a lower priority thread. In this example we have three threads with high, low and medioum priority (threads high, low and med). Threads high and low both use the same resource that is protected by something like a semaphore in order to get mutual exclusion.
As we start the example, thread high is sleeping, waiting for a specified time. Thread low runs and grabs the resource. Then treads high and med both wake up and thread high preempts the thread low. It attempts to grab the resource but is forced to wait since the resource is already grabbed by thread low. Since thread med is the highest priority thread that wants to run it may now run, meaning that the high priority thread wants for the low priority thread to release the resource but the low priority thread doesn't run because its priority is lower than that of thread med.
So we found a situation where a high priority thread (high) actually may not run as long as a lower priority thread (med) doesn. This is called priority inversion. A common solution is that the thread that has grabbed a resource gets a current priority that is equal to that of the highest priority thread that waits for that resource. That is called priority inheritance.
Signals
Signals can be sent between to signal events. Since they don't contain any further information than that an event has happened, signals are more suited for synchonisation purposes than for exchanging information.
Signals are used in the way that one thread waits for a signal (and is then put in its waiting statue). When another thread sends the signal in question, the first thread wakes up and is put in its ready or running state.
Message queues/Mailboxes
Message queues are very useful for exchanging information between threads. A classic use is for client-server applications. The client puts a message in the server message queue. The message specifies what service is requested. When the message is put into the queue, the server thread wakes up and executes the request. Often the client expects an answer from the server that contains the result of the request. In this case, the client waits for a message in its queue and wakes up when the server has put its reply into the queue.
Some kind of message queue system is implemented in most operating systems. Sometimes they are called mailboxes, but according to some definitions they are only called mailboxes when the size of the message content isn't limited.
Wikipedia also has something to say about message queues.
Systems
Nothing here either...
OSEK/VDX
Introduction
OSEK/VDX started as an effort from German and French automotive industry to reduce costs of software development in distributed real-time control by standardising non-applikation dependant software parts. If a common real-time OS was used, it would be easier to integrate software from different manufacturers into the same contol unit. Such an OS could also be the base for other software packages, handling the communication and network management between Electronic Control Units (ECUs).
OSEK is an abbreviation for the German term Offene Systeme und deren Schnittstellen für die Elektronik im Kraftfahrzeug" (English "Open Systems and the Corresponding Interfaces for Automotive Electronics") while VDX stands for "Vehicle Distributed eXecutive".
Currently OSEK covers three areas:
- OSEK Operating System.
- OSEK Network Management.
- OSEK Communication layer.
Only the OSEK RTOS is covered here. For further information on the other parts see the OSEK/VDX home page.
OSEK RTOS Overview
Warning: This section is not finished, and is written as a reminder to the author himself only!
Note: OSEK threads are called tasks.
- Conformance classes (
The following conformance classes are defined:
· BCC1 (only basic tasks, limited to one request per task and one task per priority, while
all tasks have different priorities)
· BCC2 (like BCC1, plus more than one task per priority possible and multiple requesting
of task activation allowed)
· ECC1 (like BCC1, plus extended tasks)
· ECC2 (like BCC2, plus extended tasks without multiple requesting admissible)
- Two task types: Basic tasks (can not be waiting - one shot) and extended tasks (convensional, can be waiting)
- Priority ceiling protocol for shared resources.
- Non-preemtive, preemptive or mixed-mreemptive scheduling - tasks can be chosen to be preemptable or not.. Non-preemptable tasks save resources.
- Supports "application modes" (compare with Rubus red schedules, but application modes can also change ISRs and extended (compare with Rubus blue) tasks). OSEK does not require the possibility to change app mode after the os has been started (stupid!!).
- Three ISR categories:
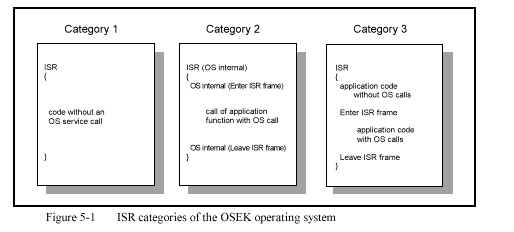
- Events (only provided for extended tasks).
- Alarms
Rubus
Tornado/VxWorks
This page has had
visits since 2002-03-11
Return to Home